Attention Learning Notes & Summary
Positional Encoding
位置编码应当满足的性质:
- 位置唯一: 同一位置的编码应当与序列总长度无关.
- 相对位置编码: 两个位置之间的attention应当与绝对位置无关而仅受相对距离影响, 对于特定任务需要能区分前后关系.
- 远距衰减: 平均而言, 距离较近的token获得更多的注意力.
- 语义聚合: 平均而言, 一对语义相似的token比一对语义无关的token获得更多的注意力, 即使前者相对距离较远.
ALiBi
ALiBi = Attention with Linear Biases, 是一种简单的相对位置编码.
只需给Attention Score计算加上线性偏置项: \[ a_{i,j}=\mathbf q_i^\mathsf{T}\mathbf k_j-m|i-j|, \]
其中 \(m\) 为非负超参数, 不同注意力头可以取不同的 \(m\). 此处取负绝对值才能满足位置编码的远距衰减性质.
RoPE
论文: RoFormer: Enhanced Transformer with Rotary Position Embedding.
RoPE = Rotary Position Embedding, 通过旋转 \(\mathbf q,\mathbf k\) , 实现相对位置编码 (尽管形式上类似于绝对位置编码).
为了在 \(\mathbf q,\mathbf k\) 中加入位置信息并满足相对位置编码性质, 我们希望找到函数 \(f_q, f_k\), 满足存在函数 \(g\) 使得 \[ \langle f_{q}(\mathbf {x}_{m},m),f_{k}(\mathbf {x}_{n},n)\rangle=g(\mathbf {x}_{m},\mathbf {x}_{n},m-n). \] 以下假定attention隐藏维度等于词嵌入向量维度, 即 \(d_h=d\). 我们先考虑 \(d=2\) 的简单情况. 根据二维向量的几何性质, 把向量写作复数, 考虑旋转变换: \[ \begin{align} f_{q}(\mathbf {x}_{m},m)&=(\mathbf {W}_{q}\mathbf {x}_{m})e^{i m\theta},\\ f_{k}(\mathbf {x}_{n},n)&=(\mathbf {W}_{k}\mathbf {x}_{n})e^{i n\theta},\\ g(\mathbf {x}_{m},\mathbf {x}_{n},m-n)&=\mathrm{Re}\left[(\mathbf {W}_{q}\mathbf {x}_{m})^{\mathsf H}(\mathbf {W}_{k}\mathbf {x}_{n})e^{i(m-n)\theta}\right]. \end{align} \]
其中 \(\mathsf H\) 表示共轭转置. 写成实矩阵形式就是 \[ \begin{align} \mathbf R_m &= \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix},\\ f_{q}(\mathbf {x}_{m},m)&=\mathbf R_m(\mathbf {W}_{q}\mathbf {x}_{m})=\mathbf R_m\mathbf q_m. \end{align} \]
对于 \(\mathbf k\) 同理. 所以 \[ (\mathbf R_m\mathbf q_m) ^ \mathsf T (\mathbf R_n\mathbf k_n) = \mathbf q_m ^ \mathsf T (\mathbf R_m^\mathsf T \mathbf R_n)\mathbf k_n=\mathbf q_m ^ \mathsf T (\mathbf R_{n-m})\mathbf k_n. \] 对于 \(d>2\) 的情况, 不妨假定 \(d\) 是偶数, 则可以把整个向量按两个数一组划分, 分别执行旋转操作. 因为内积具有可拼接性, 一开始要求的等式仍然成立. 写成矩阵形式就是 \[ \mathbf{R}_{\Theta,m}^d= \begin{pmatrix} \cos m\theta_1 & -\sin m\theta_1 & 0 & 0 & \cdots & 0 & 0 \\ \sin m\theta_1 & \cos m\theta_1 & 0 & 0 & \cdots & 0 & 0 \\ 0 & 0 & \cos m\theta_2 & -\sin m\theta_2 & \cdots & 0 & 0 \\ 0 & 0 & \sin m\theta_2 & \cos m\theta_2 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2} & -\sin m\theta_{d/2} \\ 0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2} & \cos m\theta_{d/2} \end{pmatrix} \] 可以选择 \(\Theta=\left\{\theta_i=10000^{-2i/d},i\in[0,1,\ldots,d/2-1]\right\}\).
可以注意到, RoPE的最终公式和正余弦位置编码非常相近. 事实上, 尽管正余弦位置编码是绝对位置编码, 但是其设计就是为了满足和RoPE类似的相对位置编码性质, 即对于编码 \(\{\mathbf p_n\}\), 存在函数 \(g\) 使得
\[ \langle \mathbf p_m,\mathbf p_n\rangle=g(m-n). \]
关于RoPE中 \(\theta_i\) 的取值选择沿用正余弦位置编码中的取值的原因, 可以参考文章 Transformer升级之路:1、Sinusoidal位置编码追根溯源 和 Transformer升级之路:18、RoPE的底数选择原则.
KV Cache
KV Cache用于在推理阶段加速decoder部分的矩阵乘法, 避免GPT自回归中相同前缀产生的大量重复计算.
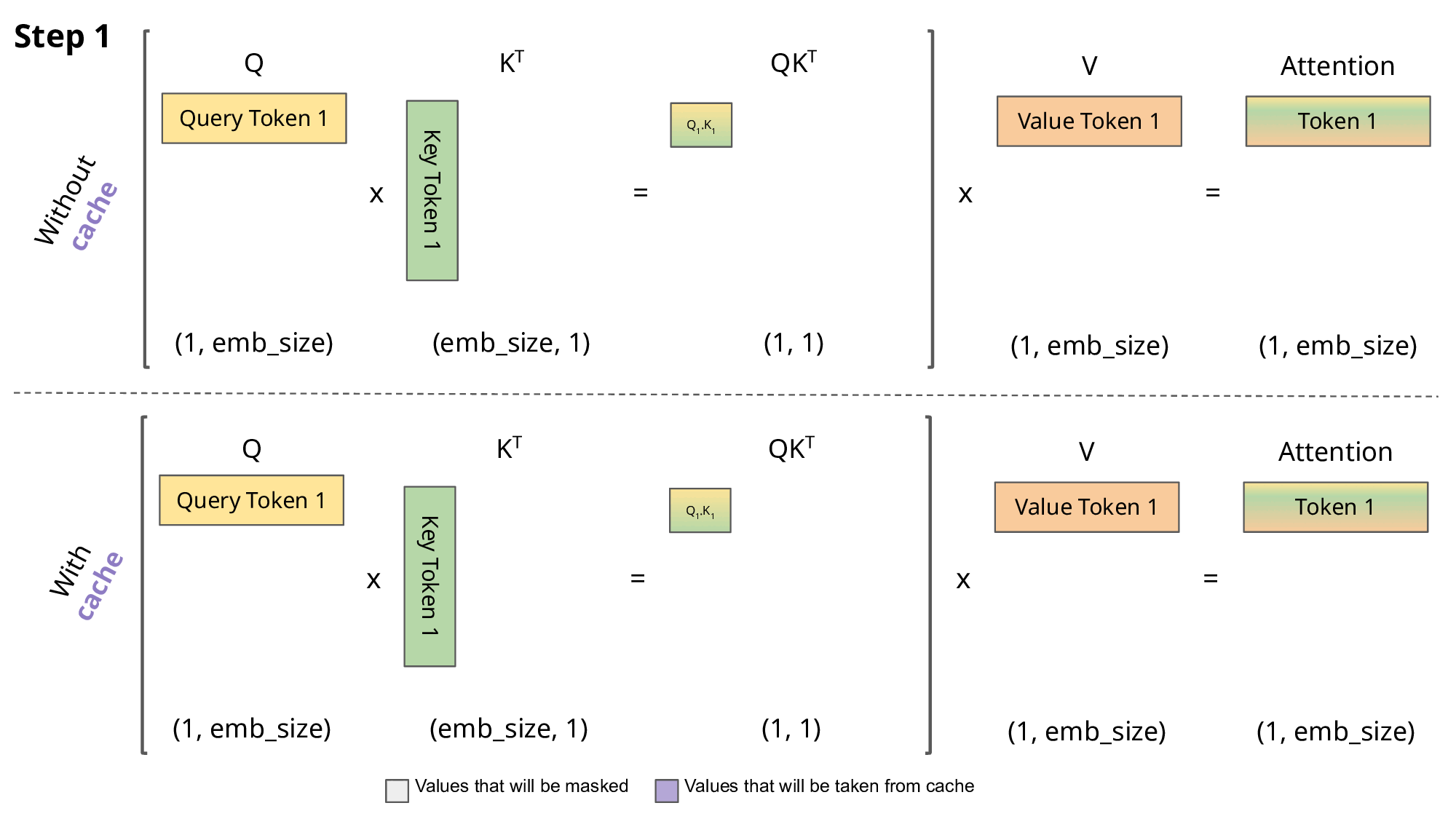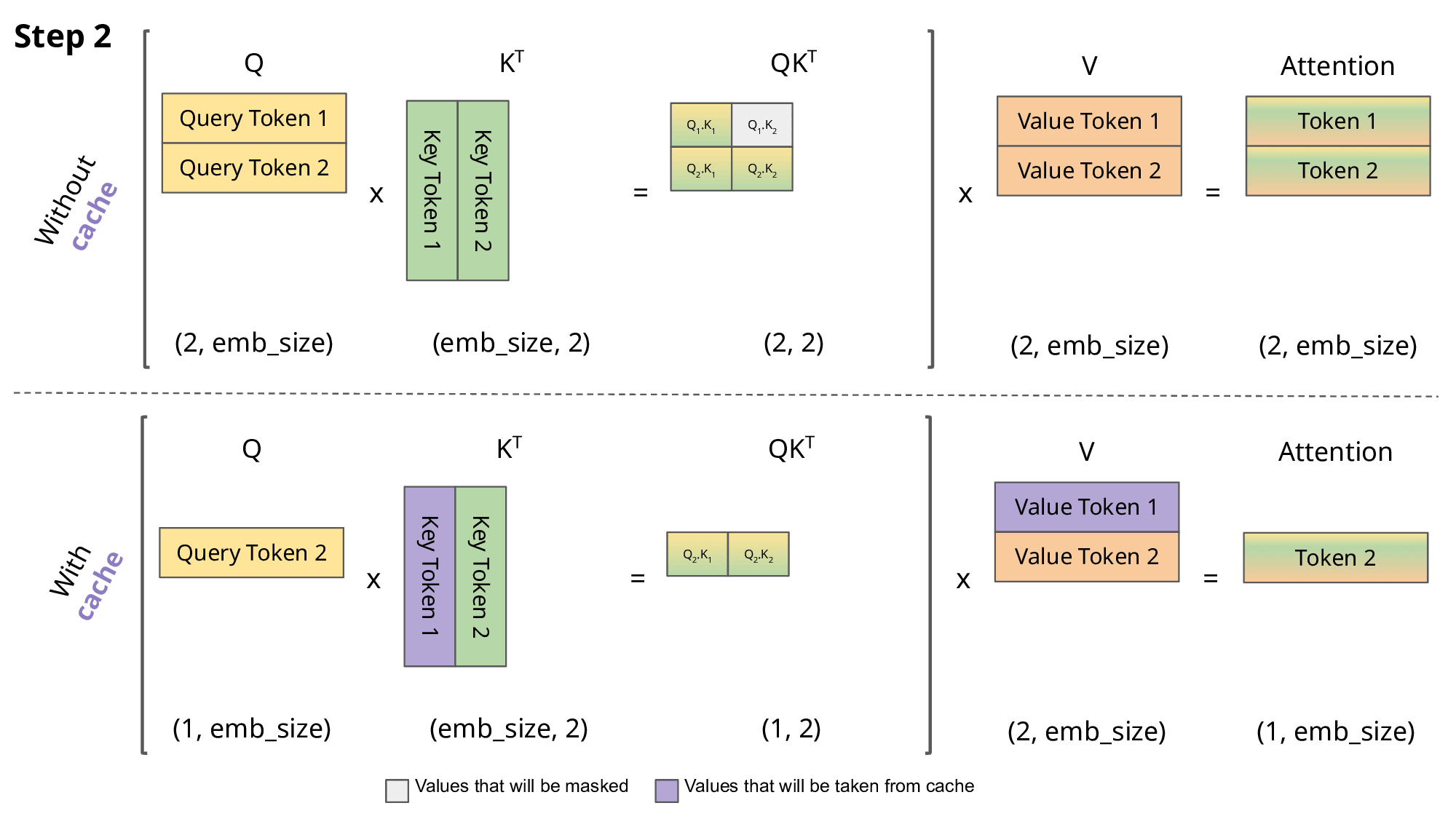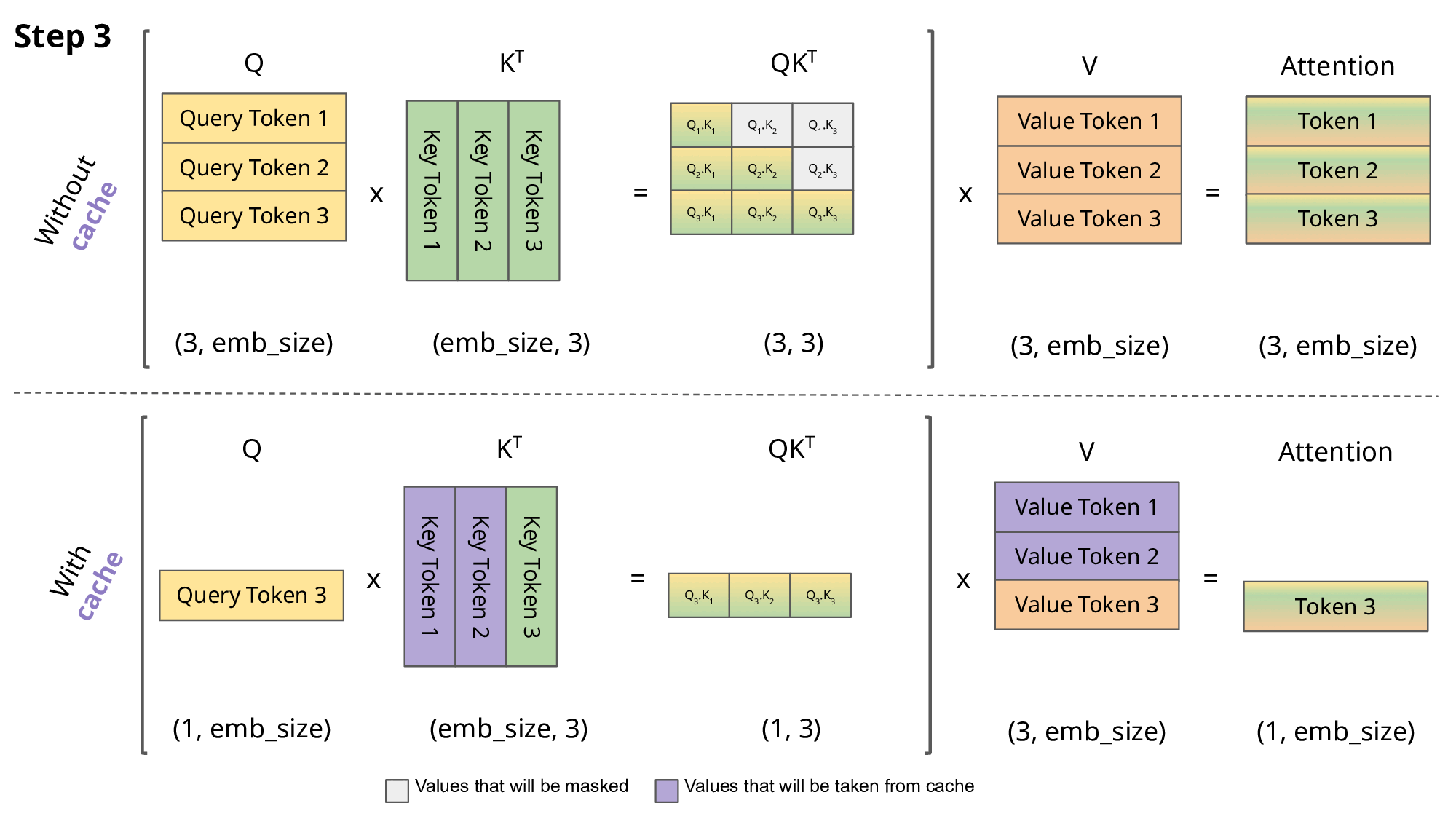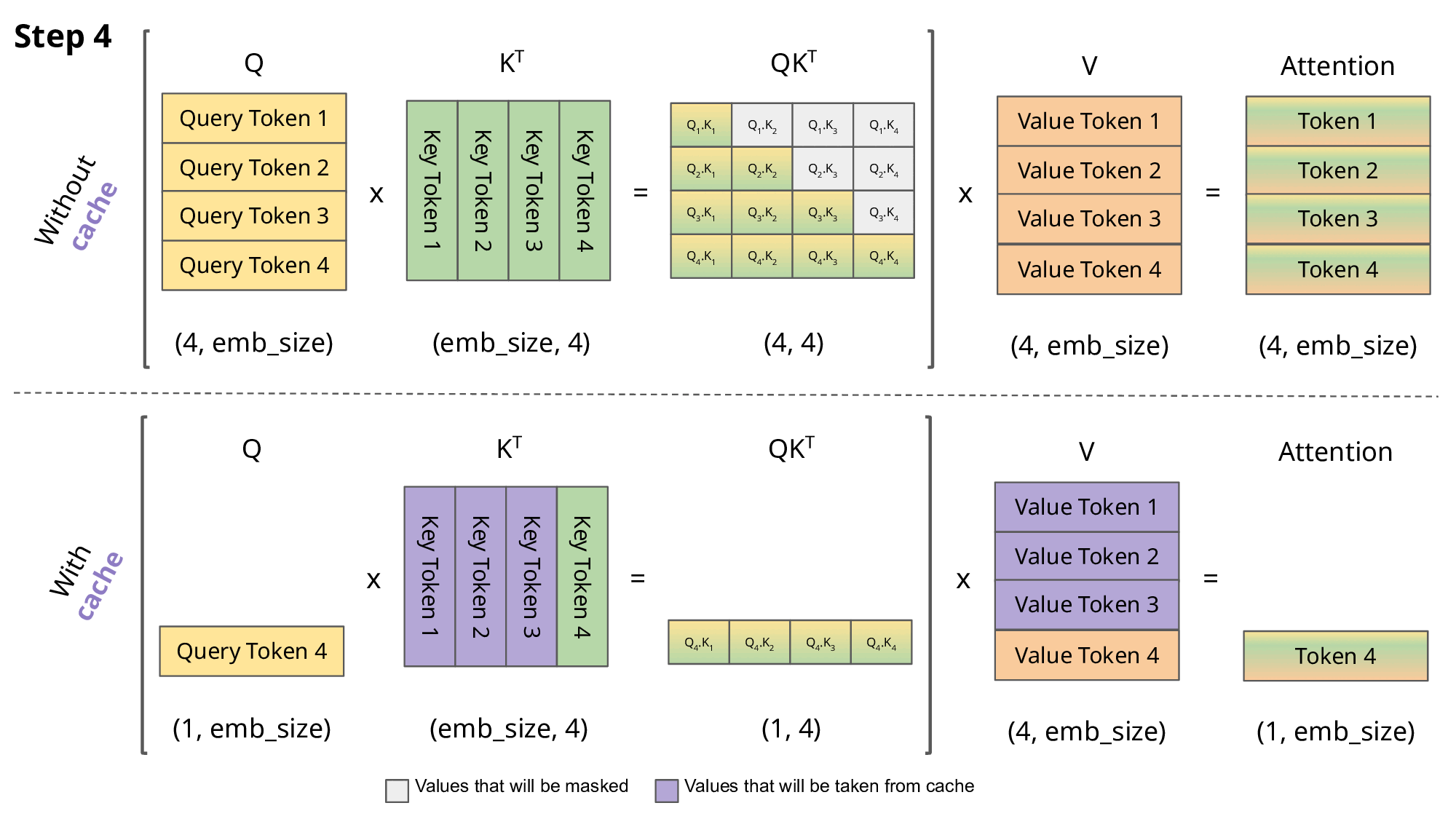
每次输出一个新的token, 不需要重新计算 \(\mathbf Q\mathbf K^\mathsf{T}\). 因为decoder掩码去掉了所有旧token对新token的注意力, 所以我们只需要计算新token的 \(\mathbf q\) (此处为横向量) 对整个 \(\mathbf K\) (已缓存)的注意力 \(\mathbf q\mathbf K^\mathsf{T}\), 取softmax后再与 \(\mathbf V\) (已缓存)相乘得到新的token.
值得注意的是, KV Cache会在模型推理时占用大量显存, 因此减小KV Cache是Transformer的一个重要的优化目标.
Flash Attention
参考文章: 大模型推理--FlashAttention.
Flash Attention算法能减少attention计算过程中的显存占用, 同时利用GPU中空间很小但可以高速访问的SRAM (Static RAM)完成所有矩阵运算, 并减少矩阵放入/取出SRAM的次数, 实现加速attention计算的效果. 以下为Flash Attention-2主要思路:
- 对 \(\mathbf Q,\mathbf K,\mathbf V\) 在行(文本长度 \(N\))的维度上分块, 外层循环将 \(\mathbf Q_i\) 载入SRAM, 内层循环将 \(\mathbf K_j, \mathbf V_j\) 载入SRAM, 计算 \(\mathbf Q_i\mathbf K_j^{\mathsf T}\).
- 计算row softmax时, 为了避免指数运算的数值溢出, 我们改为计算safe softmax, 其中需要用到row max. 由于row max无法在attention分块时计算, 而我们希望只将 \(\mathbf Q,\mathbf K,\mathbf V\) 载入SRAM一次, 因此我们需要在枚举 \(j\) 的同时维护前缀max等变量, 利用max的结合性和同底指数的可加性来更新结果.
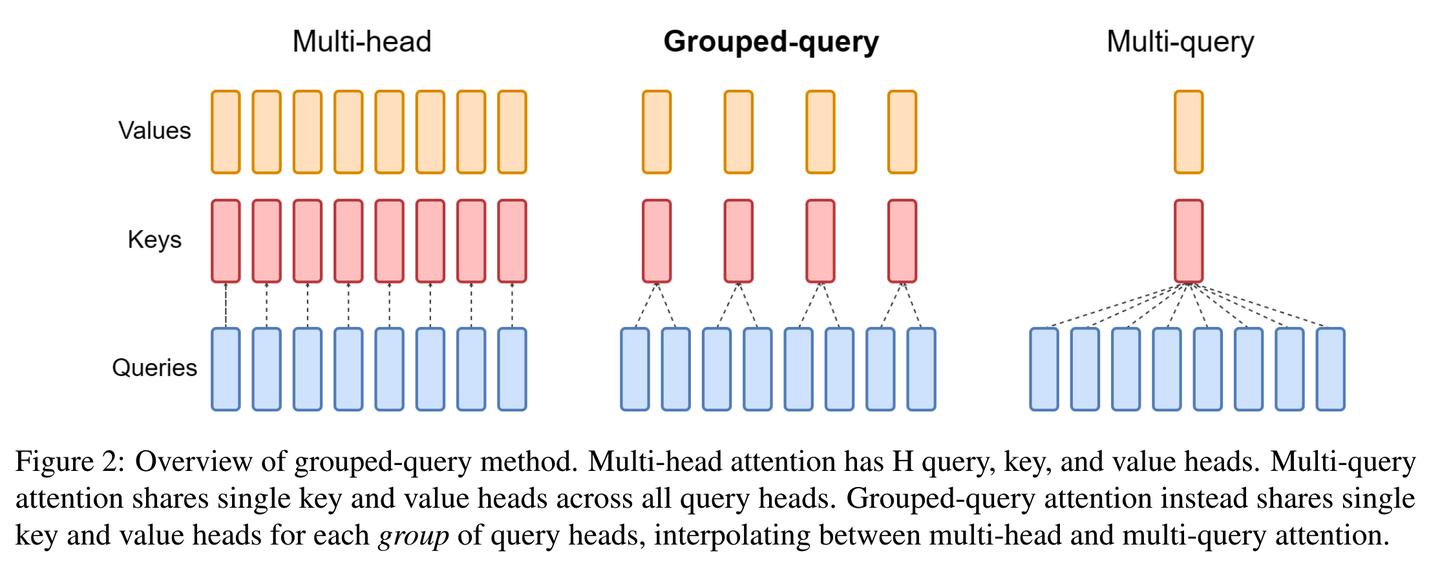
MHA Variations (for Reducing KV Cache)
MHA = Multi-Head Attention
MQA & GQA
MQA = Multi-Query Attention, 所有注意力头有不同的 \(\mathbf Q\) , 共享一份 \(\mathbf K, \mathbf V\).
更generalized的是GQA = Grouped-Query Attention, 将注意力头和对应的 \(\mathbf Q\) 分成多组, 一组共享一份 \(\mathbf K, \mathbf V\).
两者都是牺牲模型性能来减小KV Cache显存占用. 对比MLA, 可以把MQA/GQA看作是用一组不可学习的固定映射来压缩 \(\mathbf K, \mathbf V\).
MLA
参考文章: 速读 deepseek v2(一) —— 理解MLA, 缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA.
论文: DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.
MLA = Multi-head Latent Attention, 通过低维矩阵 \(\mathbf C^{KV}\) 代替 \(\mathbf K\) 和 \(\mathbf V\) 来节省显存, 同时还维持和MHA相当的模型推理速度和性能. 为了保证推理速度, 实际中并没有将 \(\mathbf c^{KV}\) 映射回 \(\mathbf k\) 和 \(\mathbf v\), 而是根据矩阵乘法结合律, 将相应参数矩阵 \(\mathbf W^{UK}\) 和 \(\mathbf W^{UV}\) (上标 \(U\) 表示升维) 和其他系数矩阵相乘结果预处理 (以下为 \(\mathbf W^Q\) 吸收 \(\mathbf W^{UK}\) 推导, 同理 \(\mathbf W^O\) 可以吸收 \(\mathbf W^{UV}\)): \[ \mathbf q_i^\mathsf{T}\mathbf k_j=(\mathbf W^Q\mathbf x_i)^\mathsf{T}(\mathbf W^{UK}\mathbf c_j)=\mathbf x_i^\mathsf{T}((\mathbf W^{Q})^\mathsf{T}\mathbf W^{UK})\mathbf c_j. \]
如果使用RoPE位置编码, 会在\(\mathbf W^Q\) 和 \(\mathbf W^{UK}\) 之间插入矩阵 \(\mathbf R_{i-j}\) , 导致无法预处理. 解决方法: 将 \(\mathbf q, \mathbf k\) 向量延长一小段, 专门用来记录RoPE信息, 不参与低维压缩, 推理时需要单独缓存, 且由于内积的可拼接性, 分别计算内积 \(\mathbf q^\mathsf{T}\mathbf k\) 再相加即可.
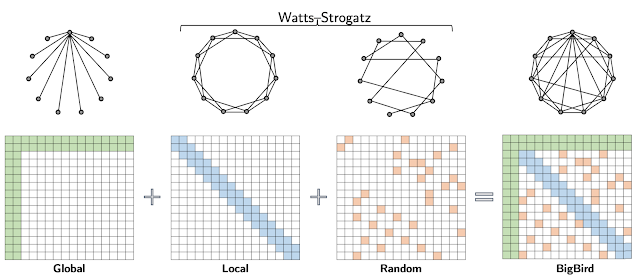
Sparse Attention
出发点: 减小自注意力的 \(\Theta(N^2d)\) 时间复杂度.
简单的稀疏注意力只选择一部分位置的自注意力进行计算. 这种选择可以基于不同的策略, 例如固定的或者学习到的模式.
Linear Attention
假如将attention计算中的softmax去掉, 则计算 \(\mathbf Q\mathbf K^\mathsf{T}\mathbf V=\mathbf Q(\mathbf K^\mathsf{T}\mathbf V)\) 仅需 \(O(Nd^2)\) 时间复杂度. 论文 Efficient Attention: Attention with Linear Complexities 中将softmax近似表达为两个softmax乘积, 即用 \(\sigma_{row}(\mathbf Q)\sigma_{col}(\mathbf K)^\mathsf{T}\mathbf V\) 代替 \(\sigma_{row}(\mathbf Q\mathbf K^\mathsf{T})\mathbf V\), 而 \(\sigma_{row}(\mathbf Q)\sigma_{col}(\mathbf K)^\mathsf{T}\) 仍然保留了softmax的行归一化性质. 我们可以抽象出正则化函数\(\rho_q, \rho_k\), 则我们希望将attention表示为 \(\rho_q(\mathbf Q)\rho_k(\mathbf K)^\mathsf{T}\mathbf V\) 的形式.
另一种思路同样从去掉softmax出发, 能得到类似的有趣结果, 参考文章 线性Attention的探索:Attention必须有个Softmax吗? (注: 文中向量的横竖有一些问题). 对于自回归问题, 与full attention的 \(\mathbf Q, \mathbf K, \mathbf V\) 长度随时间一直增长不同, linear attention用大小不变但随时间累加的 \(\mathbf S_t=\sum_{i=1}^t\phi(\mathbf K_i^\mathsf{T})\mathbf V_i\) 表示随时间更新的隐藏层状态, 因此类似于RNN模型. 与RNN一样, 这个模型同样无法遗忘信息, 缺乏提炼重点的能力, 因此可以使用类似LSTM/GRU的门控等机制, 例如参考文章 Gated Linear Attention Transformers with Hardware-Efficient Training.